iPAS AI應用規劃師 經典題庫
L22403 大數據在生成式AI中的應用
出題方向
1
用於生成式AI的大數據收集與前處理
2
支援生成式AI的大數據架構與平台
3
利用大數據優化生成式AI模型訓練
4
大數據於生成式AI模型推論與部署之應用
5
大數據在生成式AI評估與監控中的角色
6
生成式AI應用中的大數據隱私與安全
7
生成式AI與大數據整合的應用案例
8
大數據於生成式AI之挑戰與未來趨勢
#1
★★★★★
訓練大型語言模型(Large Language Model, LLM)時,使用網路爬蟲收集的大量文本數據,最可能面臨的首要大數據前處理挑戰是什麼?
答案解析
從網路爬取的大規模文本數據(如Common
Crawl)雖然量大,但其固有特性是品質不一。這包括了廣告、樣板文字、仇恨言論、重複內容、語法錯誤、非目標語言等。在將這些數據用於訓練如LLM等生成式AI模型之前,必須投入大量精力進行數據清洗、去重、過濾和品質評估,這通常是使用大數據技術(如MapReduce, Spark)處理的關鍵步驟。數據量通常是巨大的(選項A錯),格式是多樣的(選項C錯),儲存成本雖然高,但數據品質問題是影響模型性能更直接的首要挑戰(選項D相對次要)。
#2
★★★★
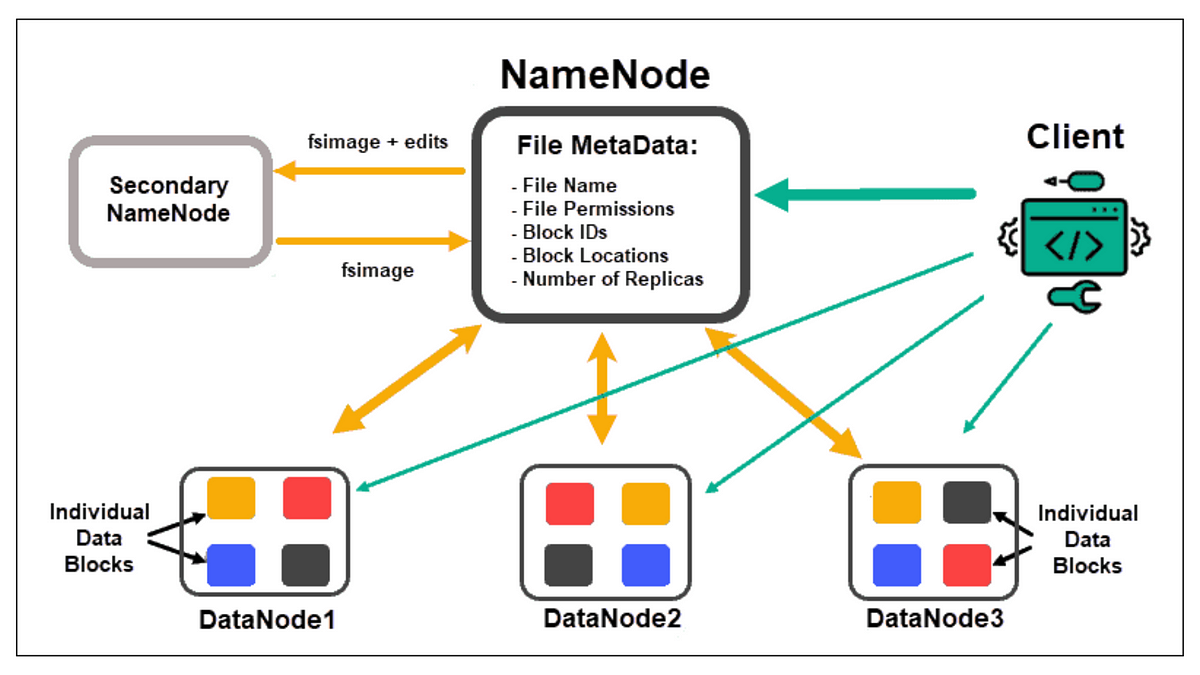
在訓練一個需要數百TB甚至PB級數據的生成式AI模型時,哪種大數據儲存方案最適合用於存放原始及處理後的訓練數據集?
答案解析
處理PB級的數據遠超出了單一伺服器或傳統關聯式資料庫的處理能力。分散式文件系統(如Hadoop Distributed File
System, HDFS)和雲端物件儲存服務被設計用來水平擴展(scale
out),能夠經濟高效地儲存和管理極大規模的數據,並提供高吞吐量的數據訪問,這對於大數據處理框架(如Spark)和大規模模型訓練至關重要。記憶體內資料庫雖然快,但不適合儲存如此龐大的數據集。
#3
★★★★★
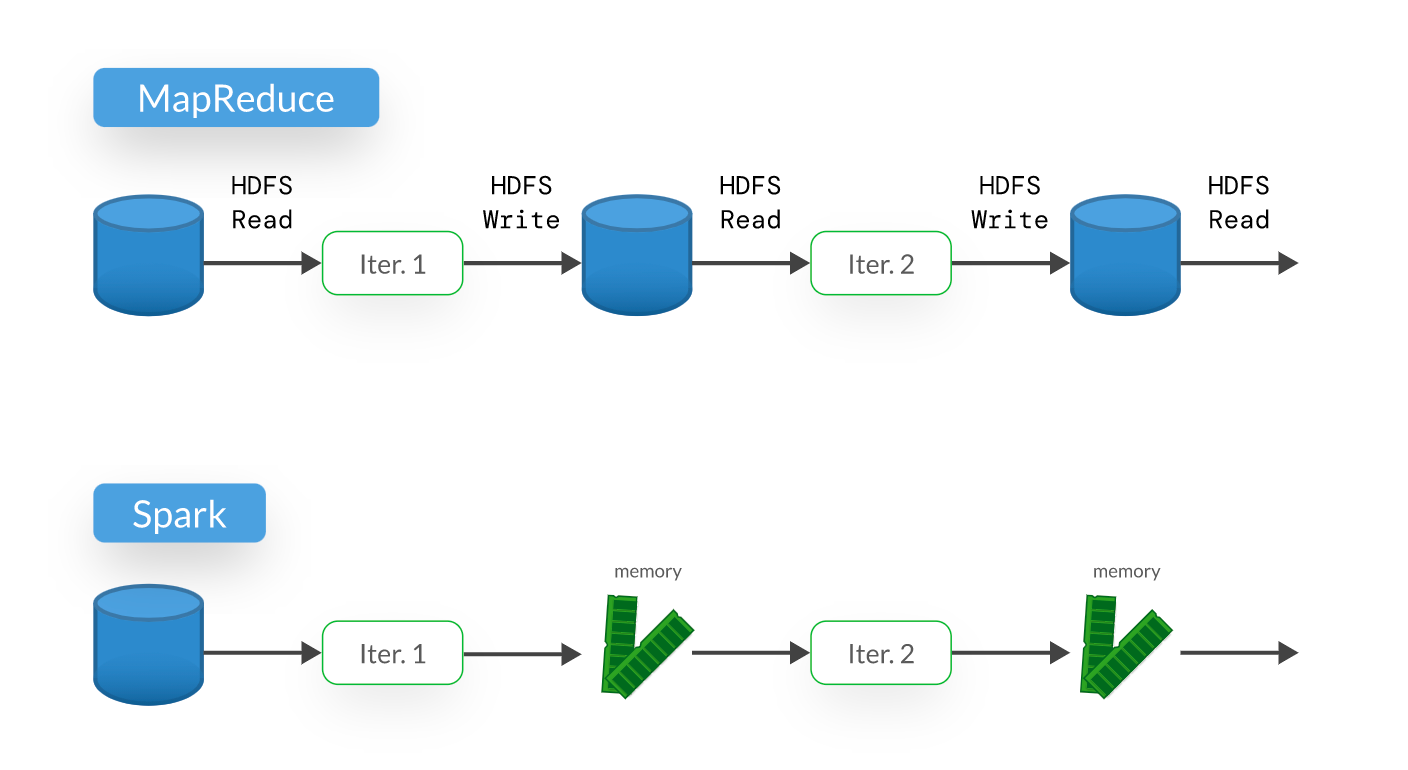
使用Apache Spark進行大型生成式AI模型(如圖像生成模型)的訓練數據前處理時,其相較於傳統MapReduce的主要優勢是什麼?
答案解析
Apache Spark的核心優勢之一是其基於彈性分散式資料集 (Resilient Distributed
Datasets, RDDs)或DataFrames/Datasets的記憶體內計算能力。對於需要多次迭代處理數據的任務(如機器學習算法、複雜的數據轉換流程),Spark可以將中間結果緩存在記憶體中,避免了像MapReduce那樣每次迭代都需要讀寫磁碟,從而顯著提高了性能。這對於涉及複雜特徵工程或多階段處理的生成式AI數據準備工作尤其有利。Spark能處理多種數據類型,具備容錯性,且是為分散式環境設計的。
#4
★★★★
當需要將一個訓練好的大型生成式AI模型(例如數十億參數的LLM)部署用於線上推論(Inference)並處理高併發請求時,通常會利用哪種大數據相關技術來分散負載?
答案解析
大型生成式AI模型的推論通常計算密集且可能需要大量記憶體。為了處理高併發的線上請求並保證低延遲,標準做法是水平擴展。這通常通過將模型打包成容器(如Docker),然後使用容器編排系統(如Kubernetes)部署多個相同的模型實例(副本)。前端的負載平衡器則負責將傳入的請求均勻地分發到這些健康的實例上,從而分散負載,提高系統的吞吐量和可用性。這種架構是雲原生和現代大規模服務部署的常用模式,也適用於大型AI模型的推論服務。僅增加單一伺服器資源(垂直擴展)有其上限。資料庫不適合儲存模型參數進行快速推論。批次處理框架不適用於低延遲的線上請求。
#5
★★★★
在監控一個部署上線的生成式AI服務(如聊天機器人)時,收集和分析大量的用戶互動日誌(如請求內容、生成的回應、用戶反饋),以便持續評估模型性能和發現潛在問題(如偏見、有害內容生成)。這體現了大數據在生成式AI生命週期的哪個階段的應用?
答案解析
生成式AI模型部署後並非一勞永逸。持續收集和分析模型在實際應用中產生的大量數據(如用戶查詢、模型輸出、用戶點擊/評分反饋等日誌)至關重要。這些大數據可用於監控模型的性能指標(如回應相關性、流暢度、安全性),檢測模型漂移(Model
Drift)、發現和量化偏見或有害內容的生成頻率,以及收集用於模型再訓練或微調的數據。這屬於模型生命週期中部署後的運維(MLOps)環節,大數據分析平台(如ELK Stack,
Splunk, 或基於Spark/Flink的流處理)在此扮演關鍵角色。
#6
★★★★★
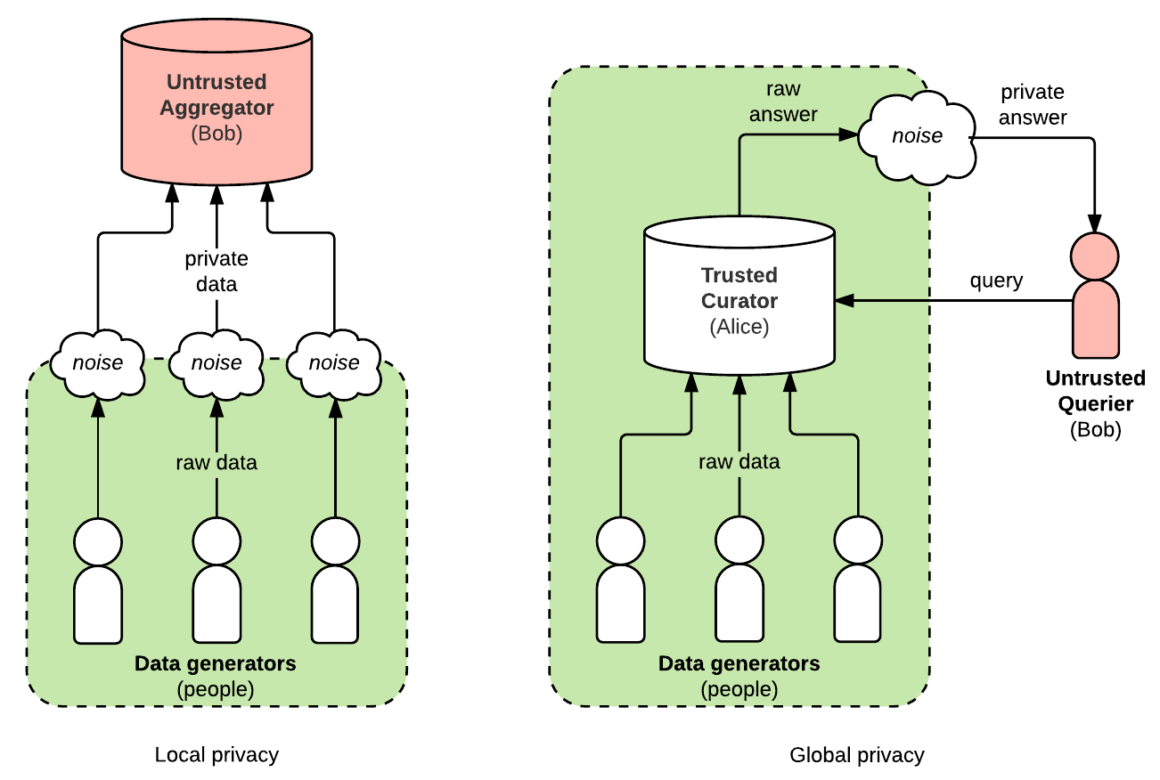
在利用包含個人身份資訊(Personally Identifiable Information, PII)的大數據集訓練生成式AI模型時,為了保護用戶隱私,哪種技術可以在保留數據統計特性的同時,降低個體數據被洩露的風險?
答案解析
差分隱私是一種強有力的隱私保護框架,它通過在數據分析或模型訓練過程中(例如在梯度更新或數據聚合時)添加精心控制的隨機噪聲,使得最終發布的結果(如模型參數、統計數據)對於數據集中是否存在任何單一個體數據不敏感。換句話說,即使攻擊者知道除某個特定用戶外的所有數據,也無法確定該用戶的數據是否在原始數據集中,從而提供了數學上可證明的隱私保障。這對於處理涉及敏感訊息的大數據集(尤其是在生成式AI可能記住並洩露訓練數據的風險下)非常重要。其他選項:數據增強和特徵工程是數據處理技術,模型壓縮是優化模型大小,它們本身不直接提供隱私保護。
#7
★★★
一家電子商務公司希望利用生成式AI自動為其數百萬種商品生成獨特且吸引人的描述文本。為了確保生成的描述與商品屬性(如顏色、材質、尺寸等)相關且準確,他們需要整合哪兩類關鍵技術?
答案解析
這個應用場景需要結合兩方面的能力:首先,需要有效管理和訪問包含數百萬商品及其詳細屬性的大數據(通常儲存在數據倉庫、數據湖或NoSQL資料庫中),這需要大數據處理技術。其次,需要一個能夠根據輸入的條件(即商品的屬性)生成對應文本的生成式AI模型,這屬於條件式文本生成(一種生成式AI)。模型需要以商品屬性數據作為輸入(prompt或condition),生成與之匹配的描述。因此,整合大數據管理和條件式生成模型是實現該目標的關鍵。
#8
★★★★
在生成式AI領域,利用超大規模數據集(如數萬億tokens的文本)訓練基礎模型(Foundation Models)時,最顯著的挑戰之一是什麼?
答案解析
訓練參數動輒數千億甚至上兆、數據量達PB級的基礎模型,需要極其龐大的計算資源,包括數千個高性能GPU/TPU,以及數週甚至數月的訓練時間。這不僅導致了極高的訓練成本(可能達數百萬甚至數千萬美元),也引發了對其巨大能源消耗和環境影響的擔憂。這種對算力的極端需求是目前大規模生成式AI發展中最核心的挑戰之一,也驅動了對更高效訓練演算法、硬體和分散式系統的研究。
#9
★★★
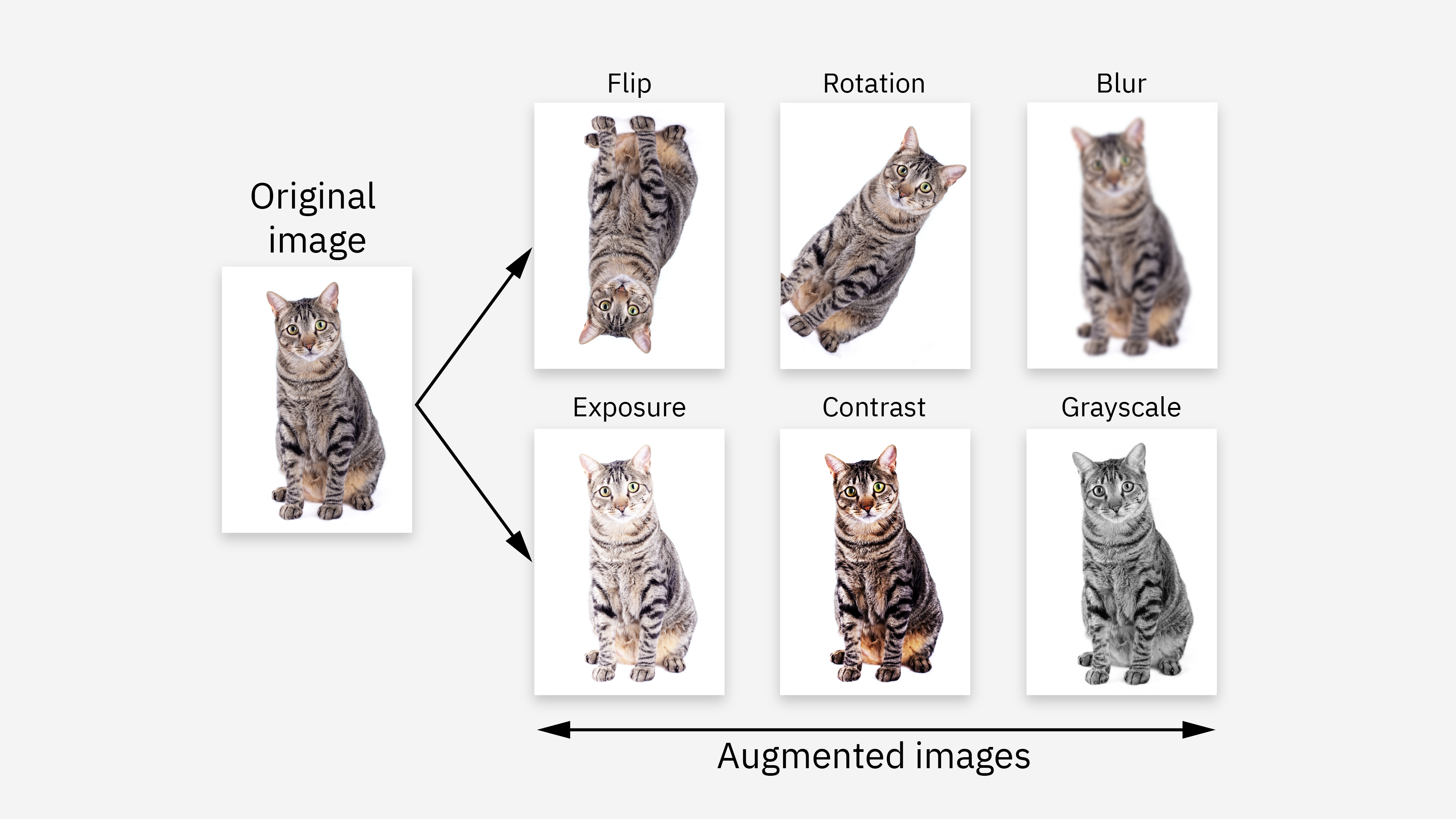
為了提高生成式AI模型訓練數據的多樣性,除了從多個來源收集數據外,還可以利用大數據集進行哪種數據前處理操作?
答案解析
數據增強是一種常用的技術,旨在通過對現有數據進行各種變換來人工擴充訓練數據集的大小和多樣性,而無需收集更多原始數據。對於圖像數據,常見的增強方法包括隨機旋轉、縮放、裁剪、翻轉、顏色抖動等。對於文本數據,則可能包括同義詞替換、隨機插入/刪除詞語、句子重排、以及利用機器翻譯進行回譯(back-translation)等。在處理大數據集時,可以應用這些增強技術來生成更多的訓練樣本,有助於提高模型的泛化能力和穩健性。去重、標準化和抽樣是其他數據處理步驟,但它們的主要目的不是增加數據多樣性。
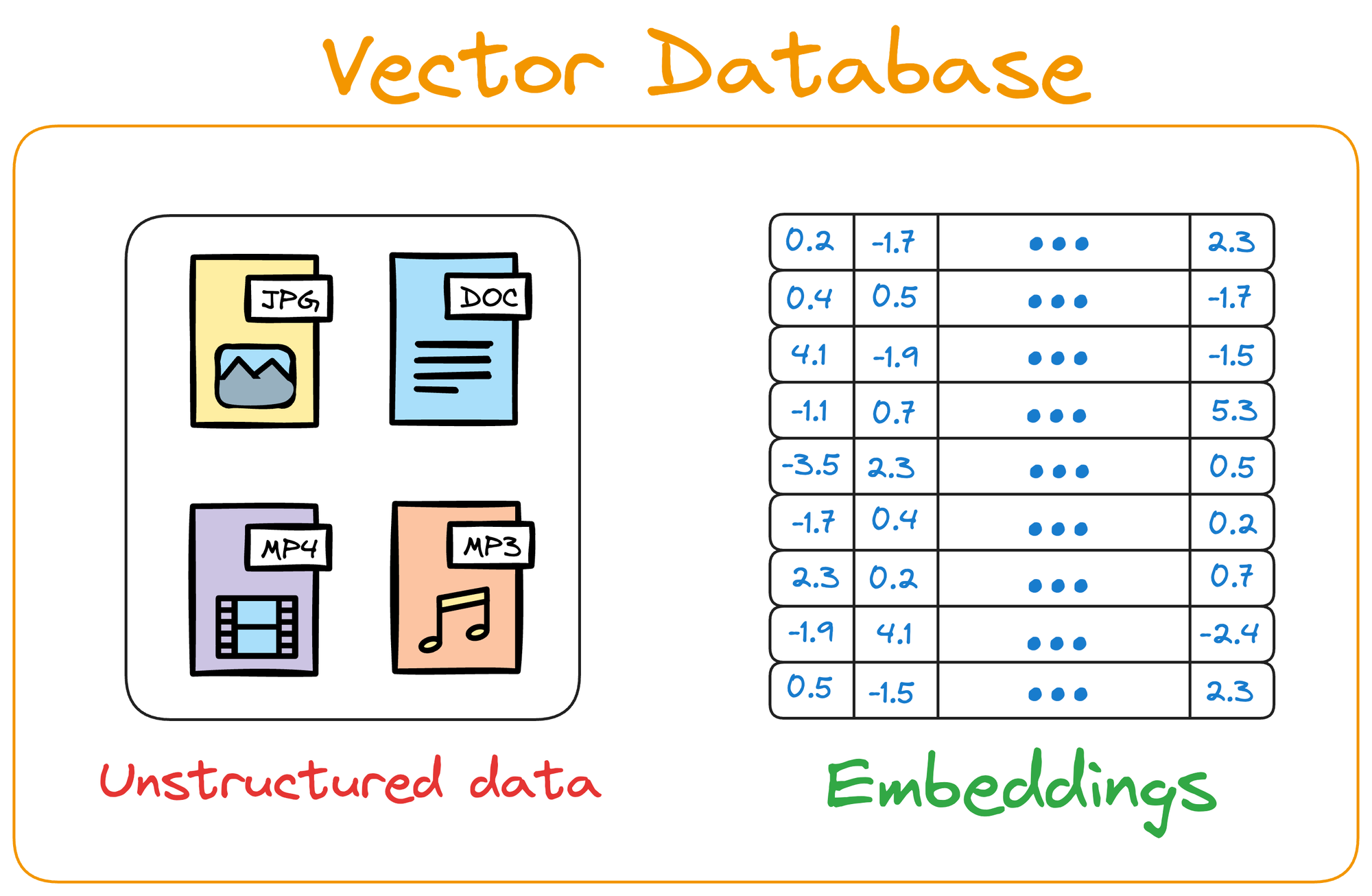
#10
★★★★
哪種資料庫類型特別適合儲存和查詢生成式AI(尤其是LLM)中常用於增強上下文理解的向量嵌入(Vector Embeddings)?
答案解析
向量嵌入是將文本、圖像或其他數據轉換為高維數值向量的表示,相似的項目在向量空間中距離較近。生成式AI,特別是LLM在進行如檢索增強生成(Retrieval-Augmented Generation, RAG)等任務時,需要高效地在大規模向量集合中查找與輸入查詢最相似的向量(即最近鄰搜索)。向量資料庫(如 Pinecone, Weaviate,
Milvus, ChromaDB)專門為此類任務設計,它們優化了高維向量的儲存、索引(如使用 HNSW,
IVF 等算法)和相似性搜索,能夠在大數據規模下實現快速、準確的向量檢索,這是其他類型資料庫難以高效完成的。

#11
★★★★
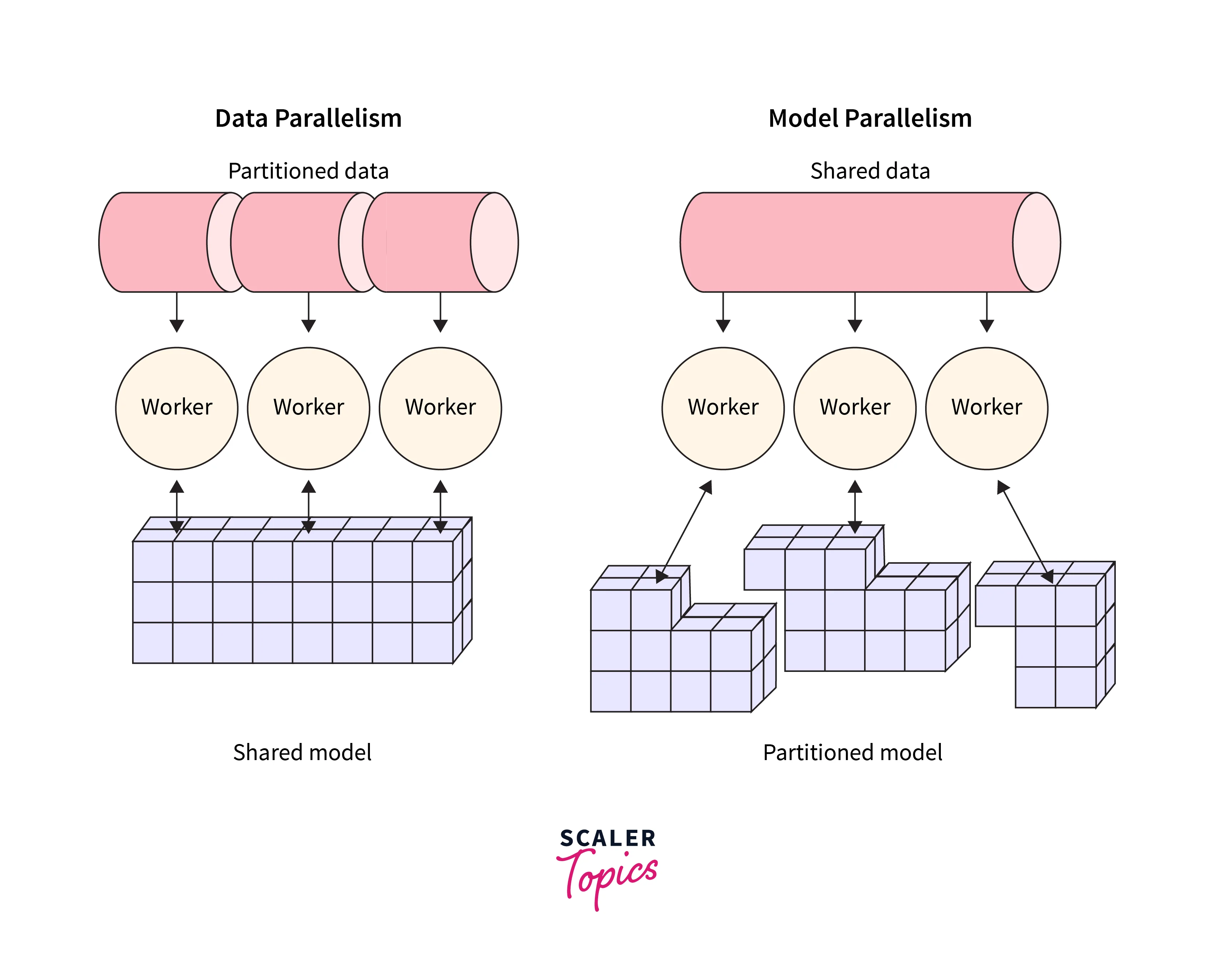
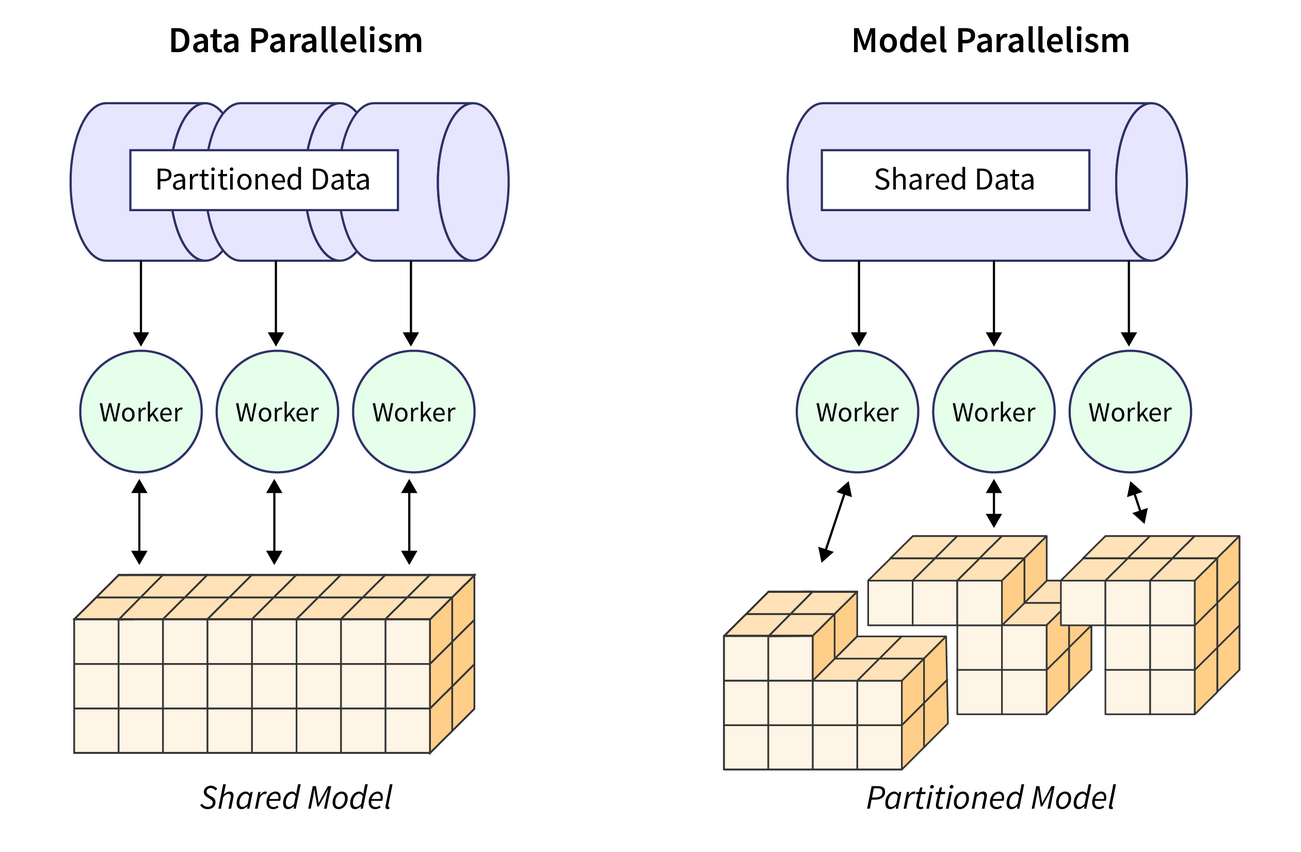
在利用大數據訓練生成式AI模型時,分散式訓練(Distributed Training)的主要目標是什麼?
答案解析
訓練大型生成式AI模型通常需要處理海量數據和巨大的模型參數,單一計算節點往往無法在合理時間內完成訓練,或者無法容納整個模型。分散式訓練通過將計算任務分配到多個節點(如多台機器上的多個GPU)上並行執行,來克服這些限制。常見的策略包括數據並行(Data
Parallelism,每個節點處理一部分數據,同步梯度)和模型並行(Model Parallelism,將模型的不同部分放在不同節點上),其核心目標是縮短訓練時間和/或支援更大規模的模型與數據集。
#12
★★★
對於需要低延遲回應的生成式AI應用(如即時圖像風格轉換),如果模型推論時間較長,可以利用大數據預處理技術做些什麼來優化用戶體驗?
答案解析
快取是一種常見的優化技術。如果某些輸入(或輸入的某部分,如用戶畫的草圖的初始向量)經常出現,或者某些計算步驟可以預先完成,可以將這些結果儲存在快速訪問的快取中(如記憶體或Redis)。當新的請求到來時,如果能在快取中找到匹配的預計算結果,就可以直接使用或作為起點,從而跳過部分耗時的計算,縮短整體回應時間。分析歷史大數據日誌可以幫助識別哪些內容適合快取。
#13
★★★★
使用A/B測試來評估不同版本生成式AI模型(例如,不同提示或微調策略的聊天機器人)的效果時,需要收集大量用戶互動數據來進行統計分析。這主要利用了大數據的哪個特性?
答案解析
A/B測試的核心是將用戶隨機分配到不同組(A組使用模型版本A,B組使用模型版本B),然後收集足夠多的用戶行為數據(如點擊率、轉換率、滿意度評分等),以統計上顯著的方式比較兩個版本的性能差異。為了獲得可靠的統計結果並檢測出可能較小的性能差異,通常需要大量的用戶樣本和互動數據,這直接體現了大數據的「量」(Volume)的特性。雖然速度、多樣性和真實性也很重要,但A/B測試成功的基礎在於足夠的數據量來支持統計推斷。
#14
★★★★
在訓練生成式AI模型時,若使用來自多個用戶的數據,但希望模型訓練在本地設備上進行,僅將聚合後的模型更新(而非原始數據)發送到中央伺服器。這種保護數據隱私的大數據處理範式被稱為什麼?
答案解析
聯邦學習是一種分散式機器學習方法,允許多個參與方(如用戶設備或機構)協作訓練一個共享模型,而無需將他們的本地原始數據發送出去。每個參與方在本地使用自己的數據訓練模型,然後只將模型的更新(如梯度或模型權重)安全地聚合到中央伺服器,用於更新全局模型。然後全局模型再分發回參與方進行下一輪訓練。這種方法特別適用於需要利用分佈在各處的敏感大數據(如手機用戶輸入、醫療記錄)進行模型訓練,同時又要保護數據隱私的場景。

#15
★★★
利用大數據分析用戶在社群媒體上的發文內容、互動模式和關係網路,來訓練一個可以生成個性化、符合用戶語氣和興趣的社群媒體貼文的生成式AI模型。這個應用整合了大數據分析與哪個生成式AI的主要能力?
答案解析
該應用場景的核心是生成社群媒體貼文,這屬於文本生成的範疇。更進一步,它要求生成的文本具有個性化特徵(符合特定用戶的風格、興趣),這是通過利用大數據分析用戶歷史行為和關係網路來實現的。模型需要學習用戶的語言模式、常用詞彙、主題偏好等,並在生成文本時體現這些特徵。因此,這是大數據分析與個性化/風格化文本生成技術的結合。
#16
★★★
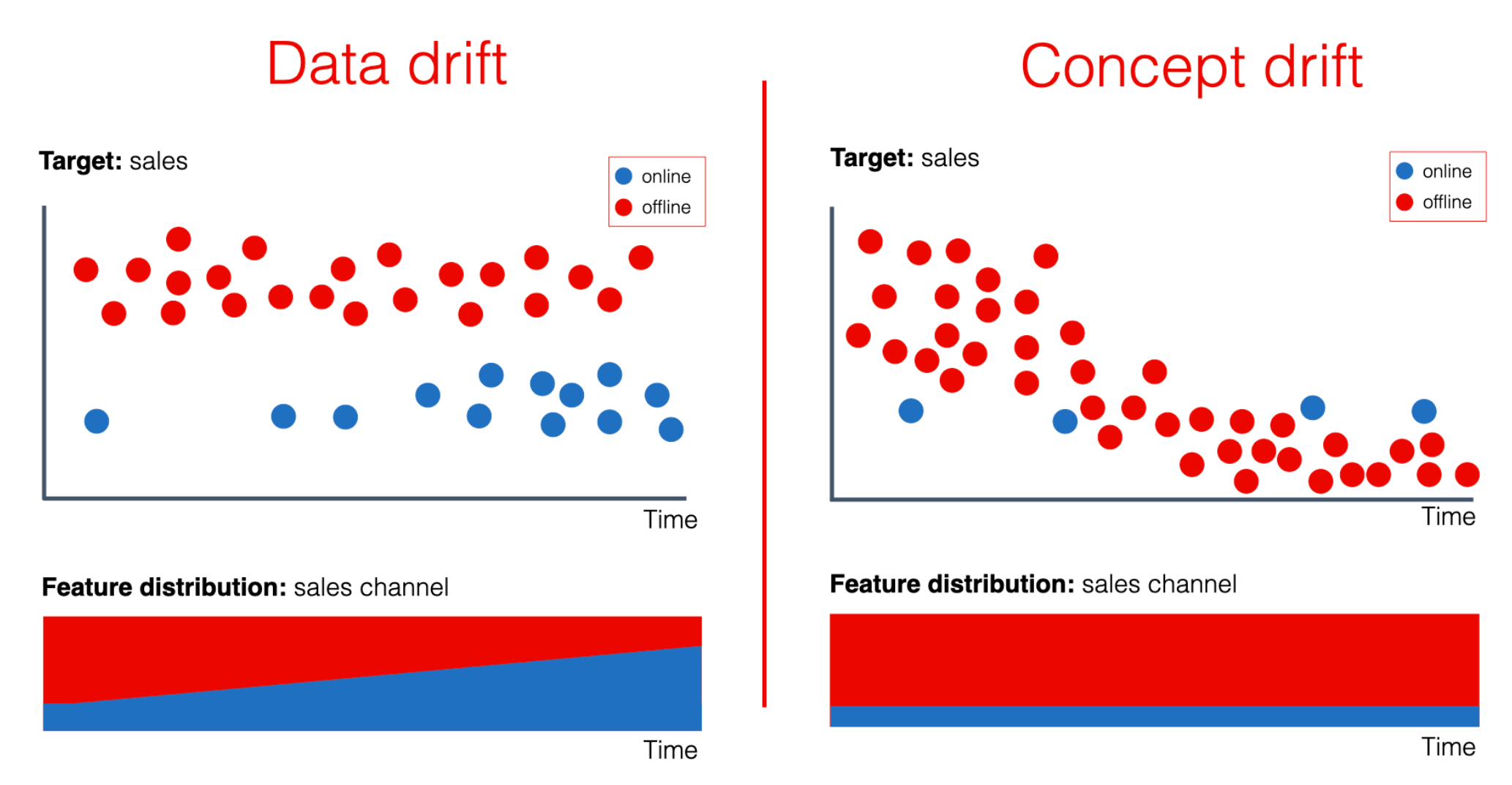
「數據漂移」(Data Drift)是指生產環境中的實時數據分佈逐漸偏離了訓練模型時所用的數據分佈。在大數據驅動的生成式AI應用中,數據漂移可能導致什麼主要問題?
答案解析
生成式AI模型是從訓練數據中學習模式和分佈的。當實際應用中的數據(例如,用戶查詢的類型、主題、風格隨時間變化)與訓練數據產生顯著差異時,模型基於舊數據學到的知識可能不再適用於新數據,導致其性能下降。例如,一個基於舊新聞數據訓練的文本摘要模型,可能無法很好地摘要關於新興事件的報導。因此,監控數據漂移並定期使用新數據重新訓練或微調模型,是維持生成式AI服務品質的關鍵挑戰,而這需要持續的大數據監控與處理能力。

#17
★★★★
在準備用於訓練生成式AI模型的圖像大數據集時,進行數據標準化(例如,將所有圖像縮放到相同尺寸、歸一化像素值)的主要目的是什麼?
答案解析
來自不同來源的圖像數據可能具有不同的尺寸、解析度、色彩空間和像素值範圍。在將這些數據輸入神經網路(如GAN或Diffusion
Model)進行訓練之前,通常需要進行標準化處理。將圖像縮放到統一尺寸可以使模型處理固定大小的輸入。歸一化像素值(例如,縮放到[0, 1]或[-1, 1]範圍,或進行零均值單位方差標準化)有助於梯度下降等優化演算法更穩定地工作,加速模型收斂,並可能提高最終性能。這一步驟確保了數據的一致性,是許多機器學習和深度學習流程中的標準預處理環節。
#18
★★★★★
Ray是一個流行的開源框架,常用於大規模AI和Python應用。在生成式AI領域,Ray特別適合用於處理哪項涉及大數據和複雜計算的任務?
答案解析
Ray提供了一個簡單而強大的API,用於構建和運行分散式應用程式。它特別擅長處理需要大量計算資源和並行處理的AI工作負載。Ray Core提供了底層的分散式原語(如Tasks和Actors),而其上的函式庫(如Ray Train, Ray Tune,
Ray Serve)則分別針對分散式模型訓練、大規模超參數搜索/優化以及可擴展的模型推論服務提供了高級抽象。因此,Ray被廣泛應用於加速和擴展大型生成式AI模型的訓練、實驗和部署流程。

#19
★★★
在使用大數據進行生成式AI模型訓練時,「資料平行處理」(Data Parallelism)是一種常見的分散式策略,其基本原理是什麼?
答案解析
資料平行處理是最常用的分散式訓練方法之一。其核心思想是:將大型訓練數據集劃分成多個子集(mini-batches),同時在多個計算單元(workers,通常是GPU)上保留完整的模型副本。每個worker獨立地使用分配給它的數據子集計算梯度。然後,通過某種機制(如參數伺服器或AllReduce算法)將所有workers計算出的梯度進行聚合(例如求平均),並用聚合後的梯度來更新所有模型副本的參數。這樣可以顯著加快處理整個大型數據集所需的時間。選項A描述的是模型平行處理(Model
Parallelism)。
#20
★★★★
對於一個需要處理大量不同用戶請求的生成式AI服務,為了優化資源利用率和成本,可以採用哪種基於大數據請求模式分析的部署策略?
答案解析
用戶請求量通常不是恆定的,會有高峰和低谷時段。自動擴縮容是一種雲端運算和大規模服務管理中的關鍵技術。它通過持續監控服務的負載指標(這些指標本身就是一種大數據流),並根據預設的規則(例如,當平均CPU利用率超過70%時增加實例,低於30%時減少實例),自動調整後端運行的服務實例(如模型推論容器)的數量。這樣可以在需求高峰時保證服務性能和可用性,在需求低谷時減少資源使用,從而優化成本效益。這需要一個能夠收集和分析負載大數據並觸發擴縮容操作的監控和管理系統(如Kubernetes
HPA)。
#21
★★★
在評估生成式AI模型(如LLM)的輸出是否包含偏見(Bias)時,僅僅依賴小樣本的人工評估可能不夠全面。利用大數據分析可以如何輔助偏見檢測?
答案解析
偏見檢測是一個複雜問題。大數據方法可以通過系統性地、大規模地測試模型在特定場景下的行為來提供更全面的視角。這包括:(1)
構建包含大量針對不同群體的測試案例(如「描述一位[職業]」);(2)
收集模型對這些案例的大量生成結果;(3) 利用自然語言處理(NLP)工具(如情感分析、詞嵌入關聯性分析)和統計檢驗,量化分析模型輸出中是否系統性地出現對某些群體不利或刻板的描述。例如,分析不同性別代詞與特定職業或形容詞的共現頻率。這種基於大數據的量化評估比小範圍人工檢查更具規模性和客觀性。
#22
★★★
當生成式AI應用需要處理來自歐盟用戶的大數據時,哪項法規對個人數據的收集、處理和保護提出了嚴格要求,是必須遵守的重要合規性框架?
答案解析
GDPR是歐盟範圍內關於數據保護和隱私的法規,對任何處理歐盟居民個人數據的組織(無論其地理位置如何)都具有約束力。它規定了數據處理的原則(如合法性、公平性、透明性、目的限制、數據最小化、準確性、存儲限制、完整性和保密性),並賦予數據主體多項權利(如訪問權、更正權、刪除權、限制處理權、數據可攜權、反對權)。在利用大數據訓練或運行生成式AI應用時,如果涉及到歐盟用戶的個人數據,必須確保符合GDPR的要求,否則可能面臨巨額罰款。HIPAA主要關乎美國的醫療資訊隱私,SOX關乎財務報告,ISO
27001是資訊安全管理體系的國際標準。
#23
★★★★
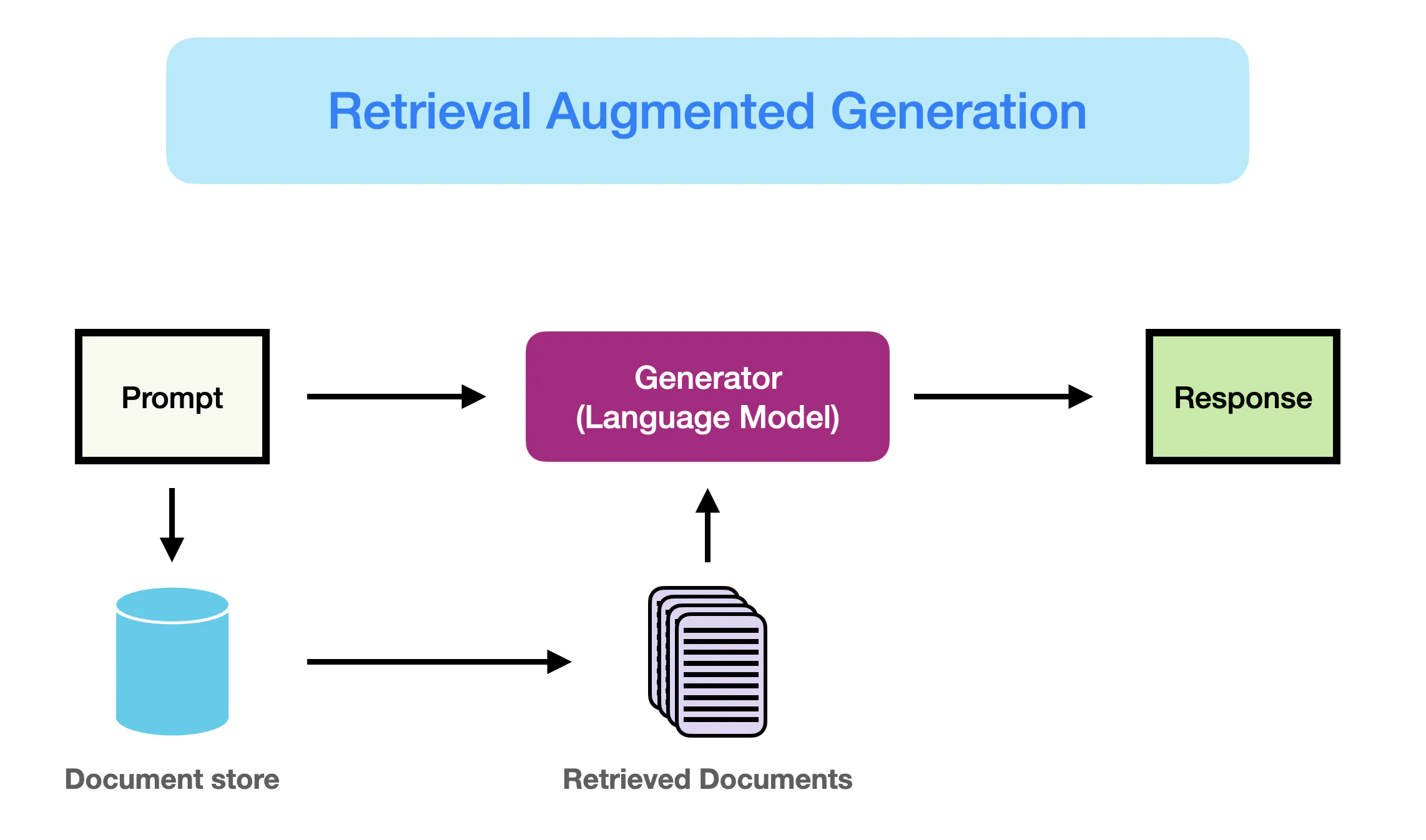
檢索增強生成(Retrieval-Augmented Generation, RAG)是一種結合了大型語言模型和外部知識庫的技術。在大數據背景下,RAG中的「檢索」步驟通常涉及什麼?
答案解析
RAG旨在通過結合預訓練LLM的生成能力和從外部知識源(如公司內部文檔、專業知識庫)檢索到的最新或特定領域資訊,來提高生成內容的準確性和相關性,並減少「幻覺」。其工作流程通常是:1. 將外部知識庫(可能是非常大的文檔集合)進行切塊、轉換為向量嵌入,並存儲在向量資料庫中建立索引。2.
當用戶提出查詢時,將查詢也轉換為向量嵌入。3. 在向量資料庫中執行相似性搜索,找出與查詢向量最相關的幾個文檔片段(這一步是關鍵的檢索步驟,涉及大數據索引和搜索)。4. 將原始查詢和檢索到的相關文檔片段一起作為上下文(context)提供給LLM。5.
LLM基於這些訊息生成最終的回答。這個檢索步驟是利用大數據(向量索引)技術來增強生成模型的典型應用。
#24
★★★★
生成式AI模型(尤其是大型模型)可能「記住」並在輸出中無意洩露其訓練數據中的敏感訊息(如個人姓名、地址、代碼片段)。從大數據治理的角度來看,這引發了對哪項原則的擔憂?
答案解析
大型生成式模型是通過學習海量訓練數據中的模式來工作的。研究表明,在某些情況下,模型可能會過度擬合(overfit)或「記憶」訓練數據中的特定、罕見的序列,並在後續生成過程中將其重現出來。如果訓練數據包含未被充分匿名化或保護的個人身份訊息(PII)、商業機密或其他敏感內容,這種記憶和洩露就構成了嚴重的數據隱私和保密性風險。因此,在使用大數據訓練生成式AI時,採取有效的數據脫敏、匿名化技術(如差分隱私)以及對模型輸出進行過濾和監控,是負責任AI開發和部署的關鍵環節。
#25
★★★
在收集用於訓練多模態生成模型(如文本到圖像模型 Stable
Diffusion)的大數據集(如 LAION-5B)時,數據通常包含圖像和與之配對的文本描述。這種配對數據的品質對模型性能至關重要,常見的數據清洗步驟可能包括?
答案解析
像LAION這樣從網路上自動收集的大規模圖文配對數據集,不可避免地會包含品質問題。為了訓練出性能良好的多模態模型,需要進行嚴格的數據清洗。這通常包括:(1) 圖像質量過濾:去除過於模糊、解析度過低、損壞或包含水印的圖像。(2) 內容過濾:利用圖像或文本分類器篩除不適宜公開展示(Not Safe For Work, NSFW)的內容。(3) 文本質量過濾:移除過短、無意義、與圖像明顯不符或語言混雜的文本描述。(4)
可能還包括基於圖像和文本嵌入相似度的過濾,以確保圖文對的語義相關性。這些步驟有助於提高訓練數據的信噪比,從而提升最終模型的生成品質和安全性。

#26
★★★
一個需要快速處理和分析大量實時數據流(例如,監控社群媒體趨勢以動態調整生成式AI的內容策略)的場景,最適合採用哪種大數據處理架構?
答案解析
流處理架構專門設計用於處理連續不斷、實時產生的大數據流。它能夠在數據到達時立即進行處理和分析,實現低延遲的響應。這對於需要根據最新訊息快速做出決策或調整行為的應用(如實時監控、欺詐檢測、動態推薦、以及根據實時趨勢調整AI生成內容)至關重要。批次處理通常處理靜態的、累積到一定量的數據,延遲較高。數據倉儲主要用於歷史數據的分析和報告。單機腳本無法處理大規模實時數據流。
#27
★★★★
在訓練大型生成式模型時,除了數據平行處理,當模型本身過於龐大無法放入單一GPU記憶體時,會採用哪種分散式訓練策略?
答案解析
模型平行處理是解決單個計算設備無法容納超大模型問題的關鍵技術。它將一個巨大的模型切分成多個部分,並將這些部分分別放置在不同的GPU或其他計算單元上。在計算過程中,數據或中間結果需要在這些單元之間進行通信。常見的模型平行處理方式包括張量平行(Tensor Parallelism,將單個操作的計算分散)、管道平行(Pipeline
Parallelism,將模型的不同層按順序放在不同設備上,形成流水線)等。這通常與數據平行處理結合使用(例如,DeepSpeed框架中的ZeRO技術),以應對超大規模模型的訓練挑戰。梯度累加和提前停止是訓練優化技巧,但不能解決模型過大的問題。
#28
★★★
為了評估生成式AI(如文本摘要模型)輸出的品質,除了人工評估外,常用的自動評估指標如 ROUGE (Recall-Oriented Understudy
for Gisting Evaluation) 分數,通常需要將模型生成的大量摘要與對應的參考摘要(Reference
Summaries)進行比較。準備這些參考摘要本身可能涉及什麼大數據挑戰?
答案解析
像ROUGE、BLEU等自動評估指標都需要一個或多個「黃金標準」的參考輸出來與模型生成結果進行比較。對於文本摘要、機器翻譯等任務,獲取大量(成千上萬甚至更多)由人類專家撰寫或仔細審核的高質量參考文本,是一項成本高昂(人力成本)且耗時的任務。這限制了自動評估指標在大數據規模下的應用範圍和可靠性,也是為什麼通常仍需要結合小範圍的人工評估來更全面地判斷模型性能。這是數據標註和評估基準構建中的一個典型大數據挑戰。

#29
★★★★
使用大數據訓練生成式AI模型時,如果數據來源包含受版權保護的內容(如書籍、音樂、程式碼),可能會引發哪方面的法律和倫理風險?
答案解析
生成式AI通過學習訓練數據來生成新的內容。如果訓練數據中包含了大量受版權保護的作品,而未獲得合法授權,那麼模型的訓練過程本身以及其生成的內容,都可能被視為對原作者版權的侵犯。例如,模型可能會生成與訓練數據中受版權保護文本、圖像或代碼高度相似的內容。這已成為生成式AI領域一個主要的法律和倫理爭議點,涉及合理使用(Fair
Use)原則的界定、數據來源的透明度和版權歸屬等問題。

#30
★★★
一家金融機構利用其海量的歷史交易數據和客戶行為數據,訓練一個生成式AI模型來模擬市場波動或生成合成的(Synthetic)但統計特性逼真的金融時間序列數據,用於風險壓力測試或策略回測。這個應用場景主要利用了大數據的哪個價值?
答案解析
金融領域擁有大量高維度、高頻率的歷史數據。生成式模型(如基於GAN或Transformer的時間序列模型)可以學習這些大數據中蘊含的複雜相關性、波動性模式和尾部風險事件。訓練好的模型可以生成大量統計特性與真實數據相似的合成數據。這些合成數據可以用於:(1)
擴充數據集,尤其是在缺乏某些罕見事件數據時;(2) 進行壓力測試,模擬歷史上未發生過的極端市場情景;(3)
在不使用真實敏感數據的情況下進行策略回測或模型開發。這是利用大數據訓練生成模型以創造新價值(模擬、測試數據)的典型應用。
#31
★★★★★
生成式AI模型(尤其是LLM)有時會產生「幻覺」(Hallucination),即生成看似合理但實際上是虛假或與事實不符的資訊。在大數據背景下,減輕幻覺問題的策略之一是?
答案解析
幻覺是大型語言模型固有的一個挑戰,因為它們本質上是基於訓練數據中的統計模式來預測下一個詞,而不一定具備事實核查能力。檢索增強生成(RAG)是一種有效的緩解策略。通過在生成過程中引入一個檢索步驟,從一個可信賴的、可能非常龐大的外部知識庫(如維基百科、公司內部文檔、最新的新聞數據等,這些都需要大數據技術來管理和索引)中找到與用戶問題相關的具體訊息,並讓模型在生成回答時「參考」這些檢索到的事實性內容,可以顯著提高生成結果的準確性,減少憑空捏造(幻覺)的可能性。
#32
★★★★
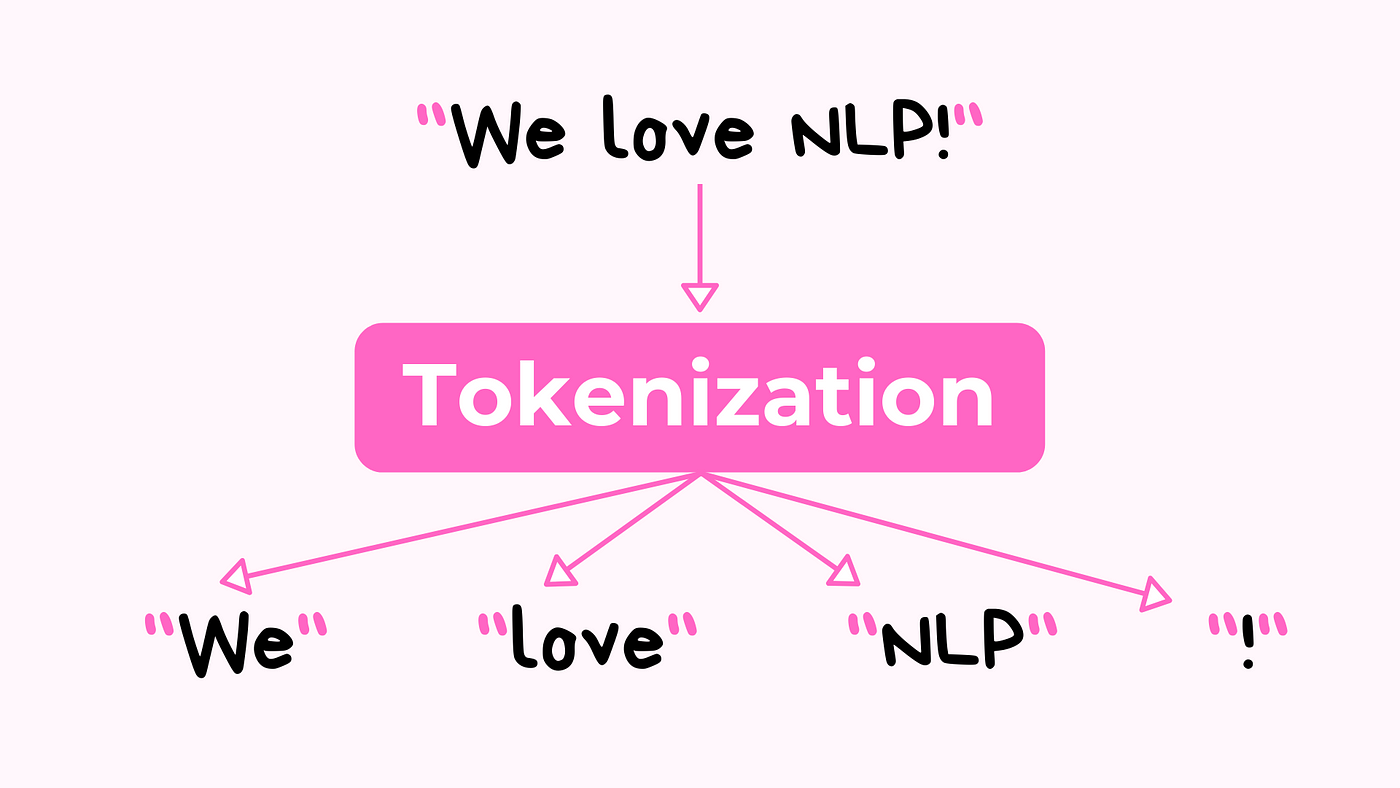
Tokenization(分詞/標記化)是處理文本大數據以訓練LLM的關鍵第一步。對於包含多種語言(如中文、英文、日文)的混合文本數據集,選擇或設計分詞器時需要主要考慮什麼?
答案解析
不同語言的分詞/標記化需求差異很大。例如,英文等基於空格分隔的語言,可以基於詞或子詞(subword,如Byte Pair Encoding - BPE, WordPiece)進行切分。而中文、日文等沒有明顯空格分隔的語言,則需要更複雜的基於字或詞的切分策略,或者同樣採用子詞方法。在處理包含多種語言的大數據集時,分詞器必須能夠穩健地處理這些差異,避免將不同語言的文本切分成無意義的片段。同時,構建的詞彙表需要足夠大且設計合理,以包含多種語言中的常見字符、子詞單元,才能有效表示輸入文本並供模型學習。
#33
★★★★
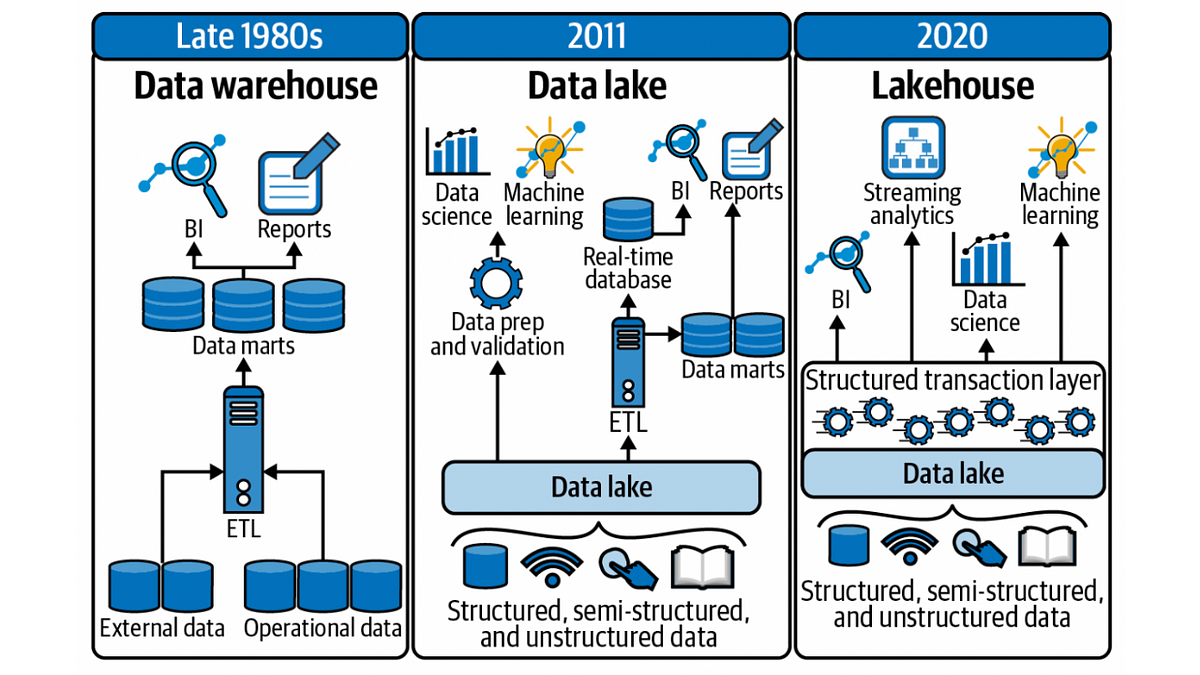
數據湖(Data
Lake)架構允許企業儲存來自各種來源的原始、半結構化和結構化大數據。相較於傳統數據倉儲,數據湖在支持生成式AI應用方面的主要優勢是?
答案解析
生成式AI模型往往需要處理多種類型、格式不一的海量原始數據。數據湖採用「讀時模式」(Schema-on-Read)策略,允許先將各種原始數據直接存入,而無需在寫入時強制轉換為統一的結構化格式(這是傳統數據倉儲Schema-on-Write的做法)。這種靈活性使得數據湖非常適合存儲用於AI/ML的異構大數據。數據科學家和AI工程師可以在需要時,再根據具體任務(如訓練一個圖像生成模型或文本分析模型)從數據湖中提取相關的原始數據,並應用適當的處理和轉換。這為探索性數據分析和靈活的AI模型開發提供了便利。
#34
★★★
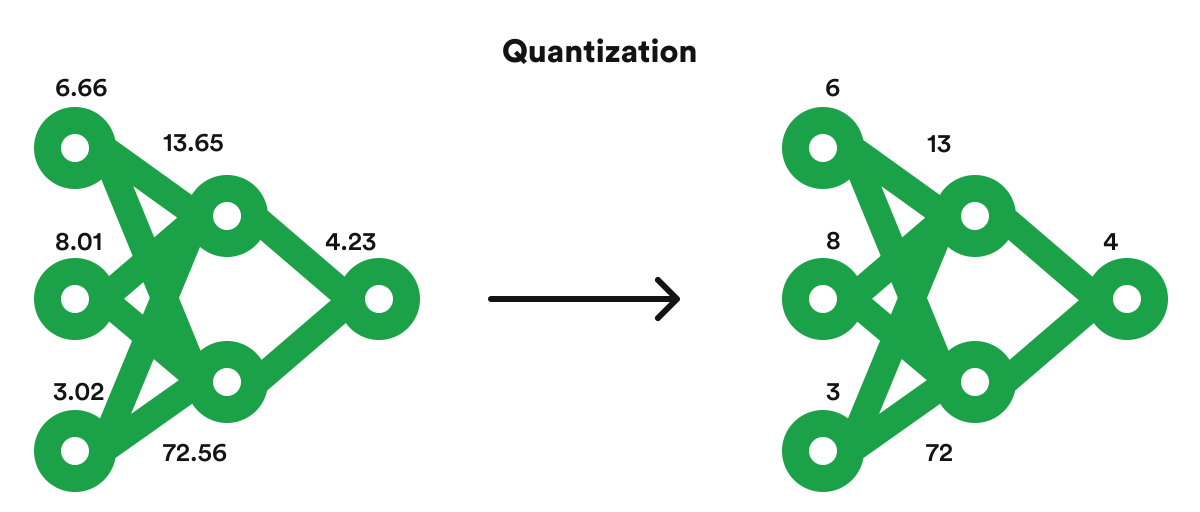
模型量化(Model Quantization)是一種常用的模型壓縮技術,用於減少生成式AI模型的大小和加速推論。在大數據服務部署中,量化的主要好處是?
答案解析
模型量化通常指將模型參數(權重和激活值)從較高精度的浮點數(如FP32)表示轉換為較低精度的表示(如FP16、INT8甚至更低)。這樣做可以:1. 顯著減小模型在磁碟和記憶體中的大小。2. 減少計算量,因為低精度運算通常更快。3. 降低功耗。這些優勢使得量化後的模型更容易部署到資源受限的環境(如邊緣設備或移動端),或者在雲端部署時能夠用更低的成本處理更多的推論請求。雖然量化可能會帶來輕微的精度損失,但通常可以通過適當的技術(如量化感知訓練)來最小化這種影響。
#35
★★
持續監控部署後的生成式AI服務,收集大量關於請求延遲、錯誤率、資源利用率等指標數據,主要目的是為了確保服務的哪個方面?
答案解析
監控服務的運行指標(如響應時間、QPS、錯誤率、CPU/GPU/記憶體使用率)是確保線上服務穩定運行的基礎,這屬於系統運維和MLOps的範疇。通過收集和分析這些實時的大數據流,運維團隊可以及時發現性能瓶頸、資源不足、服務異常或潛在故障,並採取相應措施(如擴容、重啟實例、修復bug),以保證服務對用戶來說是可靠的、隨時可用的,並且性能滿足要求。雖然倫理和數據多樣性也很重要,但這些運行指標主要關注的是服務本身的穩定性和效率。
#36
★★★
資料匿名化(Data Anonymization)是處理包含個人資訊的大數據時常用的隱私保護手段。以下哪項是對匿名化技術在生成式AI應用中侷限性的正確描述?
答案解析
雖然匿名化(如k-匿名、l-多樣性、t-相近性)旨在移除或模糊化數據中的直接和間接標識符以保護隱私,但它存在固有的挑戰。首先,匿名化程度和數據效用之間存在權衡:為了達到更高的匿名保護級別,可能需要移除或泛化(generalize)更多數據細節,這可能導致數據失去對訓練AI模型有價值的資訊。其次,即使數據經過匿名化,如果攻擊者掌握了外部的輔助數據集,仍有可能通過鏈接攻擊將匿名數據與特定個體關聯起來,從而實現重新識別。因此,匿名化並非萬無一失的隱私保護方法,尤其在處理高維度、複雜關聯的大數據時,需要謹慎評估其有效性和風險。相比之下,差分隱私提供了更強的數學保障。
#37
★★
利用生成式AI(如GAN)生成逼真的合成人臉圖像大數據集,可以用於訓練人臉識別系統,尤其是在缺乏多樣化真實人臉數據的情況下。這種做法的主要優勢是?
答案解析
生成合成數據是生成式AI的一個重要應用。在人臉識別等領域,獲取涵蓋不同年齡、性別、種族、光照、姿態的大規模真實數據集既困難又涉及隱私風險。利用GAN等模型可以生成大量外觀逼真且多樣化的合成人臉圖像。這些合成大數據可以:1. 擴充訓練集,提高模型的泛化能力,尤其是在某些類別(如少數族裔)真實數據不足時。2. 用於測試模型的穩健性。3.
在一定程度上繞開使用真實人臉數據可能帶來的隱私合規問題(儘管合成數據本身的偏見和倫理問題仍需關注)。當然,生成模型本身也需要基於真實數據進行訓練。
#38
★★★
「綠色AI」(Green AI)或「可持續AI」(Sustainable AI)的趨勢日益受到關注。在大數據和生成式AI的背景下,這主要關注什麼問題?
答案解析
訓練和運行(尤其是大型)生成式AI模型需要密集的計算,消耗大量電力,這對環境產生了顯著的影響(碳足跡)。Green AI 運動倡導在AI研究和開發中,不僅要關注模型的準確率和性能,也要重視其計算效率和環境成本。這包括開發更節能的模型架構、訓練演算法(如使用更小的模型、模型壓縮、稀疏化)、優化硬體使用、利用更高效的數據中心和可再生能源等,以降低AI技術發展對環境的負擔。這是大數據驅動的生成式AI未來發展需要面對的重要挑戰。
#39
★★
對於一個非常龐大的文本數據集(例如數TB),在進行數據清洗和預處理(如去除HTML標籤、特殊字符、重複行)時,如果單機處理速度過慢,最適合使用哪種大數據工具來加速?
答案解析
處理TB級別的數據進行清洗和轉換,遠超出了單機工具(如文本編輯器)的處理能力。分散式處理框架如Apache
Spark或Python的Dask庫,能夠將數據和計算任務分發到一個計算集群的多個節點上並行執行。它們提供了高效的API(如Spark的RDD/DataFrame API)來實現常見的數據轉換操作(如過濾、映射、聚合、去重),可以顯著縮短處理大規模數據集所需的時間。關聯式資料庫不適合處理非結構化的文本數據清洗,Git是版本控制工具。
#40
★★★★
超參數調整(Hyperparameter Tuning)是優化生成式AI模型性能的關鍵步驟。當模型訓練成本高昂且超參數組合空間巨大時,哪種基於大數據實驗結果的優化策略比傳統網格搜索(Grid Search)或隨機搜索(Random Search)更有效率?
答案解析
網格搜索會嘗試所有可能的超參數組合,隨機搜索則隨機抽樣。當超參數空間很大或單次模型訓練成本很高(如大型生成式模型)時,這兩種方法可能非常耗時且效率低下。貝葉斯優化等基於模型的優化方法,會利用先前實驗的結果(即不同超參數組合對應的模型性能,這本身就是一種需要管理的大數據)來學習一個代理模型(Surrogate Model),預測超參數與性能的關係,並智能地選擇下一個最有潛力提升性能的超參數組合進行嘗試,從而用更少的實驗次數找到接近最優的解。PBT等方法則並行訓練多個模型,並根據性能動態調整超參數和替換模型。Ray
Tune等框架支持這些高級優化策略。
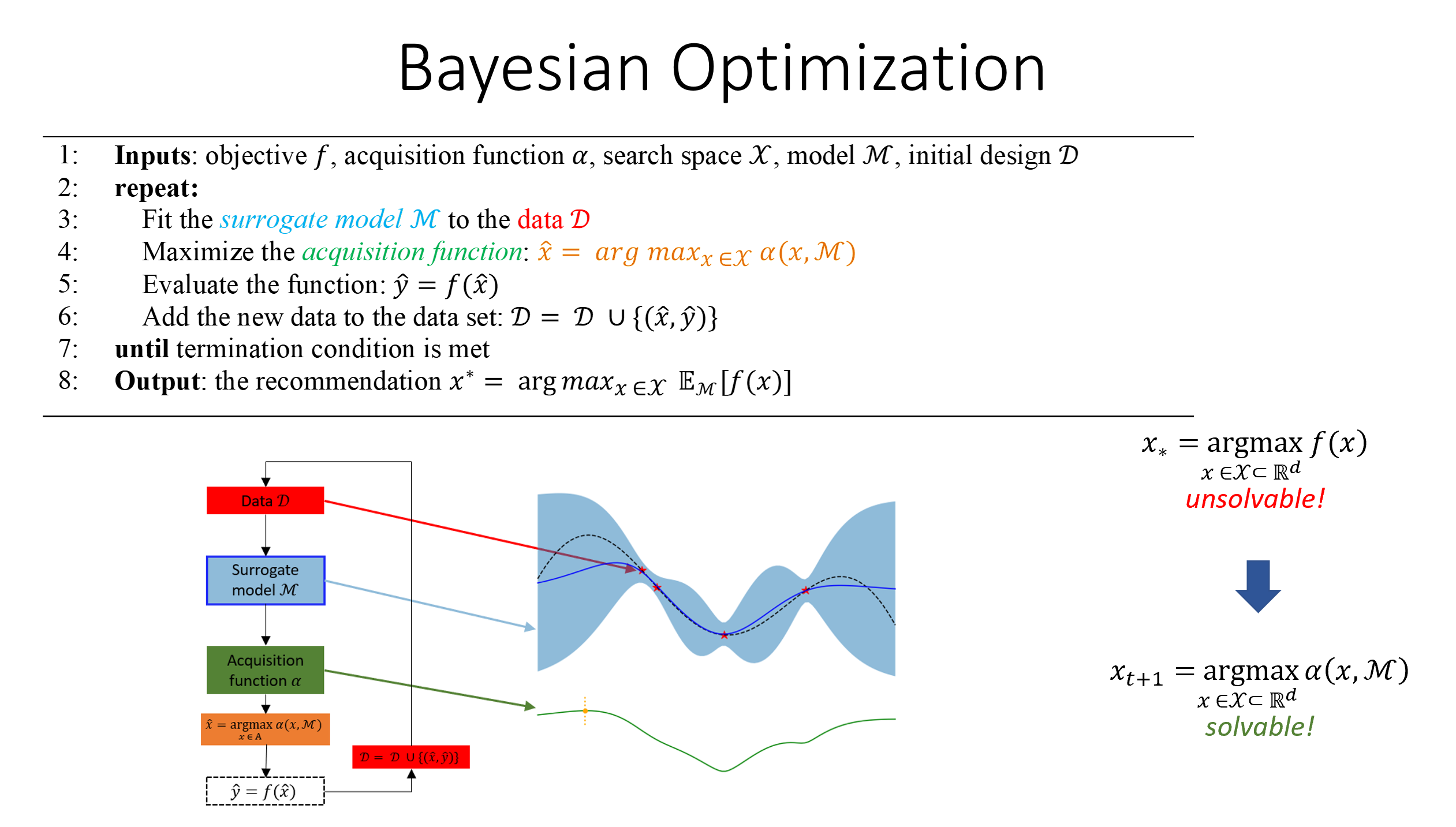
#41
★★
將訓練好的生成式AI模型部署到雲端平台(如AWS SageMaker, Google Vertex
AI)進行大規模推論服務時,平台通常提供了哪些基於大數據監控的功能?
答案解析
託管的AI平台(Managed AI
Platforms)通常內建了強大的監控和日誌功能,以幫助用戶管理部署的模型。平台會自動收集關於模型端點(Endpoint)的大量運行時數據,例如每秒查詢數(QPS)、平均/P99延遲、HTTP錯誤碼(如5xx錯誤)、以及後端計算實例的資源利用率等。這些近乎實時的大數據指標對於了解服務健康狀況、診斷問題、設置自動擴縮容策略以及容量規劃至關重要。用戶通常可以通過儀表板查看這些指標,設置告警規則,並訪問詳細的請求/響應日誌進行深入分析。
#42
★★★
為了檢測生成式AI模型是否存在數據記憶(Data
Memorization)問題(即直接複製訓練數據中的內容),可以採取哪種基於大數據比對的方法?
答案解析
檢測數據記憶需要將模型的輸出與其龐大的訓練數據進行比較。由於兩者數據量都可能非常大,人工比對是不現實的。一種可行的方法是:(1)
從訓練好的模型生成大量隨機或特定條件下的樣本。(2) 利用大數據處理技術和高效的文本比對算法(如後綴樹/數組、或者基於n-gram哈希的近似匹配方法,如MinHash),將生成的樣本與原始訓練數據集(或其索引)進行大規模比對。(3) 識別出那些與訓練數據原文存在異常高程度重疊(例如,連續幾十個或上百個詞完全一致)的生成樣本,這些可能就是數據記憶的證據。這需要強大的大數據處理能力來執行這種規模的比對。
#43
★★
在處理涉及用戶生成內容(User-Generated Content, UGC)的大數據來訓練生成式AI時,數據清洗階段一個重要的安全相關步驟是?
答案解析
用戶生成內容來源廣泛,質量和安全性參差不齊。其中可能包含不當言論、非法訊息,甚至是用於攻擊的惡意代碼(例如,試圖通過特定輸入觸發模型漏洞或進行腳本注入)。在將這些大數據用於訓練生成式AI之前,進行內容安全過濾是必不可少的步驟。這通常需要利用基於關鍵詞、正則表達式、機器學習分類器(可能本身就是另一個AI模型)或第三方內容審核服務來識別和移除這些有害或危險的內容,以防止模型學會生成這些內容或被惡意利用。
#44
★★★
利用生成式AI模型(如StyleGAN)和大量人臉圖像數據,可以創建「深度偽造」(Deepfake)應用,例如換臉。這種技術的發展同時也凸顯了大數據和生成式AI結合可能帶來的哪項主要社會風險?
答案解析
深度偽造技術利用生成式AI(特別是GAN)學習大量數據(如特定人物的影像)中的模式,然後生成高度逼真的、可以假亂真的偽造影像或音頻(例如,將一個人的臉換到另一個人身上,或模仿某人的聲音說話)。雖然這項技術有其潛在的正面應用(如影視特效),但其被濫用於製造虛假新聞、政治宣傳、色情報復、詐騙或誹謗的風險極高。這種能力對個人隱私、社會信任和訊息生態系統構成了嚴峻挑戰,是生成式AI和大數據技術發展需要重點關注和規範的倫理與社會風險之一。
#45
★★★
未來,為了訓練更強大、更通用的生成式AI模型(如通向通用人工智能 AGI
的模型),可能需要整合來自極其多樣化來源的超大規模數據(文本、圖像、音頻、影片、感測器數據、模擬數據等)。這對大數據基礎設施提出了什麼樣的挑戰?
答案解析
目前的生成式AI模型大多還是在單一或少數幾種模態上進行訓練。未來若要實現更接近人類智能水平的AGI,模型需要能夠理解和整合來自真實世界各種感知通道的訊息。這意味著需要處理的數據不僅規模會達到前所未有的Exascale(百億億級)級別,而且其異構性(種類、格式、結構的巨大差異)也將極大增加。現有的數據湖、數據處理框架、多模態資料庫等技術需要進一步發展,以應對這種極端規模和異構性帶來的儲存、計算、數據融合和管理的挑戰。構建能夠支撐這種未來需求的統一、高效、可擴展的大數據基礎設施,將是關鍵的技術瓶頸之一。
#46
★★★★
使用 Prompt Engineering 來引導大型語言模型生成特定風格或格式的文本時,為了找到最有效的 Prompt 樣板,研究人員可能會分析大量(用戶查詢,模型回應,效果評分)的數據。這種利用歷史互動大數據來優化 Prompt 的過程屬於?
答案解析
Prompt Engineering
本身是一門經驗性較強的技術,但可以通過數據分析使其更加系統化。通過收集和分析大量用戶與模型互動的日誌數據(包括輸入的提示、模型生成的輸出以及用戶對輸出的反饋或評分),可以發現哪些提示結構、關鍵詞或範例(few-shot examples)能更穩定地引導模型產生期望的結果。這種基於歷史大數據分析來迭代改進和發現最佳提示策略的方法,可以看作是數據驅動的提示優化,有助於提高與大型生成模型交互的效率和效果。
#47
★★★
在構建支持生成式AI應用的 MLOps (Machine Learning
Operations) 平台時,整合一個能夠追蹤和管理訓練數據集版本、實驗參數、模型版本和評估結果的系統至關重要。這類系統解決了大數據環境下的哪個核心問題?
答案解析
訓練生成式AI模型通常涉及多次實驗,使用不同版本的數據集、嘗試不同的超參數、代碼或模型架構。在處理大數據和複雜模型的環境下,如果缺乏系統化的管理,很容易忘記某個效果好的模型是用哪個數據集、哪組參數訓練出來的,導致實驗結果難以復現,也難以追溯問題的根源。MLOps平台中的實驗追蹤和版本控制工具(如MLflow, DVC, Weights & Biases)就是為了解決這個問題,它們記錄下每次實驗的關鍵元數據(數據版本、代碼版本、參數、指標、產生的模型文件),確保了整個開發流程的可重複性和可追溯性,這對於團隊協作、模型迭代和合規性都非常重要。
#48
★★★
在利用強化學習從人類反饋中學習(Reinforcement Learning from Human Feedback, RLHF)來微調大型語言模型時,需要收集大量人類對模型生成的多個候選回應進行排序或評分的數據。這種反饋數據的收集和管理體現了大數據在優化生成式AI哪個方面的作用?
答案解析
RLHF是讓LLM的行為與人類期望對齊(Align)的關鍵技術(例如,使其更有用、更誠實、更無害)。它包含幾個步驟:1.
收集人類對模型針對同一提示生成的不同回答進行偏好排序的數據(例如,回答A比回答B好)。2. 利用這些大量的偏好數據(這本身就是一種大數據)訓練一個獎勵模型(Reward
Model),該模型能夠預測哪個回答更符合人類偏好。3. 使用強化學習演算法,以獎勵模型的分數作為回報信號,來微調原始的LLM,使其傾向於生成能獲得更高獎勵分數(即更符合人類偏好)的回應。因此,收集和利用大量人類反饋數據是實現模型對齊的核心。
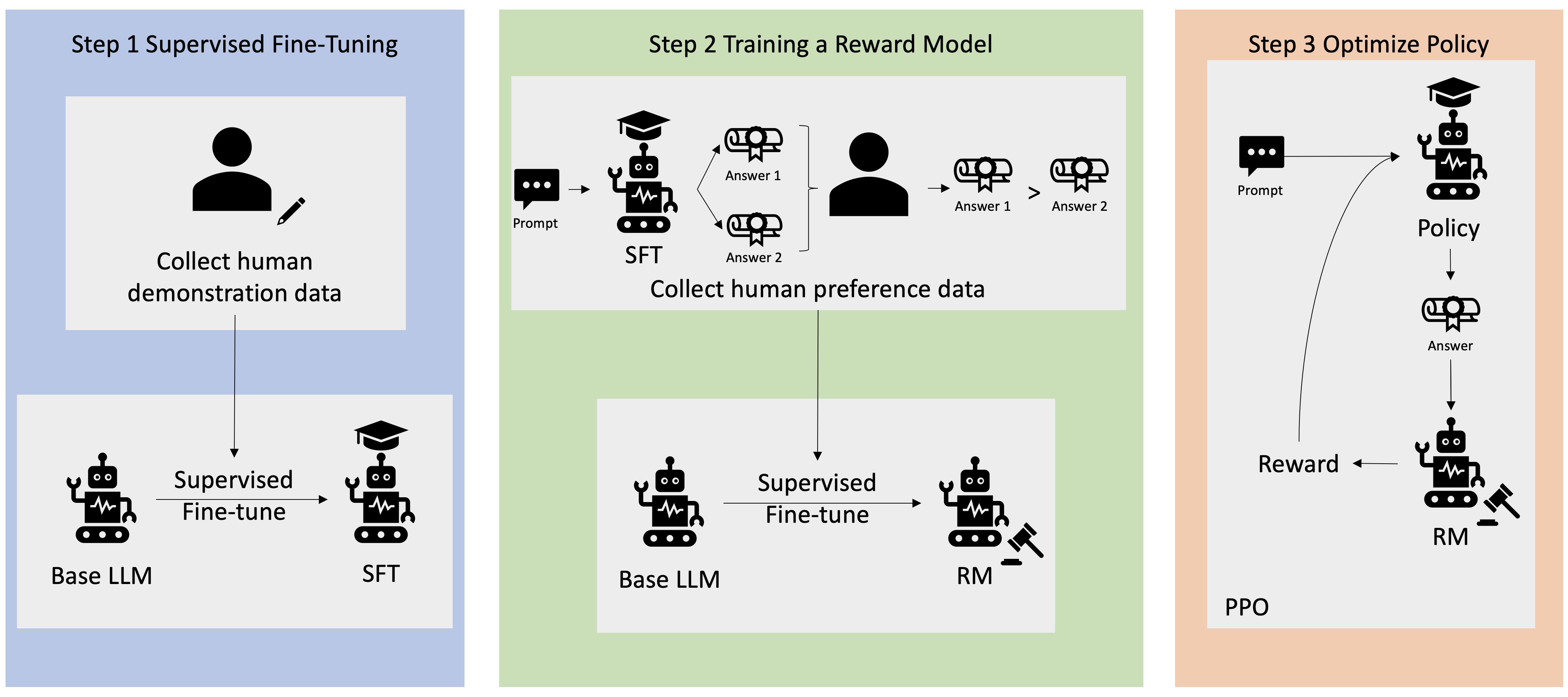
#49
★★★★
同態加密(Homomorphic Encryption)是一種允許在加密數據上直接進行計算的技術。在大數據和生成式AI的隱私保護場景中,同態加密的潛在應用前景是什麼?
答案解析
同態加密允許對密文執行計算(如加法、乘法),計算結果解密後與對明文執行相同計算的結果一致。這意味著數據所有者可以將加密後的數據發送到不受信任的環境(如公有雲)進行處理(例如,模型訓練或使用模型進行推論),而雲平台無法訪問原始的明文數據。這為處理極度敏感的大數據(如醫療記錄、金融交易)提供了非常強的隱私保障。然而,目前的同態加密技術通常計算開銷極大,速度遠慢於明文計算,這是其實際應用於大規模生成式AI訓練的主要障礙,但它仍然是一個活躍的研究領域和具有潛力的未來方向。
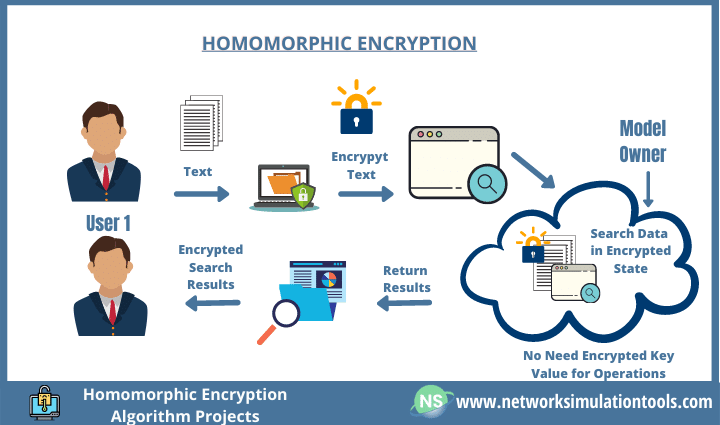
#50
★★
隨著生成式AI模型的應用越來越廣泛,其產生的大量內容(文本、圖像、代碼等)本身也構成了新的大數據。未來可能出現的一個挑戰是如何有效管理、索引、搜索和利用這些由AI生成的內容?
答案解析
當AI大量生成內容後,這些內容本身就變成了新的訊息資產和數據源。如何管理這海量的AI生成數據成為新的挑戰:(1) 如何區分人類創作和AI生成內容?(2) 如何評估AI生成內容的質量、準確性和新穎性?(3) 如何有效地索引和搜索這些內容以供複用?(4)
更重要的是,如果將大量AI生成的內容再投入到下一代模型的訓練數據中,是否會導致模型學習到錯誤或簡化的模式,造成性能退化(即所謂的模型自噬或數據污染問題)?這些都是在大數據和生成式AI交互影響下未來需要研究和解決的問題。
↑